

Today’s production and the associated processes are subject to constant change. Be it new products, the replacement of a machine, or simply the redesign of production – many causes lead to the fact that a production process has to be redesigned again and again.
At the same time, however, it is important from an economic point of view to know the processes and uncover weak points to work efficiently and ensure quality.
What is process mining and what are its challenges?
This is the subject of the increasingly popular field of process mining. The goal is to automatically generate the associated business process model from the data generated by a production system. Thus, similar to related data mining, process-based information is derived from large data streams. The advantages are obvious: one discovers the true processes in the company and not just those modeled by the process manager in a meeting. In addition, the processes can be analyzed for weaknesses using this information and other indicators of process quality.
For this, of course, the data basis (the so-called event log) must meet certain standards and contain at least the following points:
- What was done?
- When was it done?
- For which order was it done?
| Time | Task | Order | Executed by |
|---|---|---|---|
| 12-02-2020-11-37-56 | Start final assembly | IS-2193 | Assembler1 |
| 12-02-2020-11-51-44 | End final assembly | IS-2193 | Assembler1 |
This is what the event log looks like. It contains a timestamp, a reference to the order, and the performed activity. This information can be extended by any number of columns, depending on the question to be analyzed. The event log is the input and the basis for any process mining algorithm.
source: titan project Creative Commons CCBY-SA4.0
This is exactly where the biggest challenge of process mining lies. The data generated by a production system is not standardized, not all work steps are technically recorded, and not all sources of information can be included. The result is a massive manual rework and the associated fuzziness of the results. For example, if a timestamp is missing, a chronologically correct point in time has to be guessed, but a later temporal analysis becomes useless. In addition, process mining is mainly performed retrospectively for past periods. The potential of process information is thus not fully exploited.
Our goal: an automatically generated process model that represents the real process.
Process mining without programming
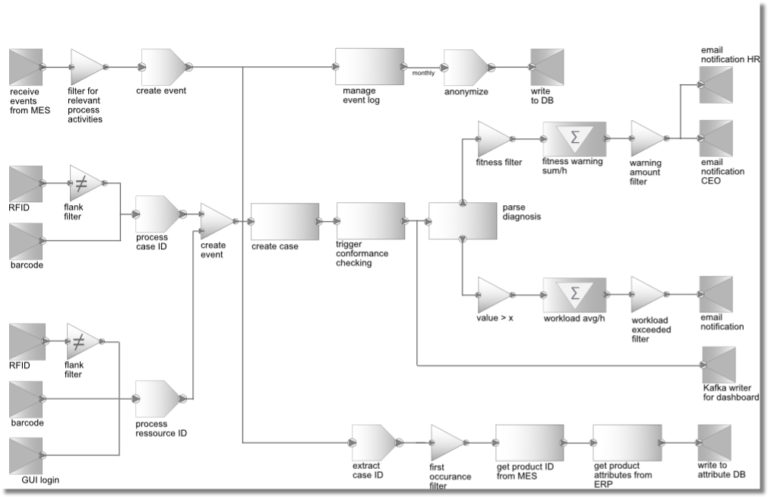
This is where titan comes into play. With a flow, different information sources can be integrated and connected. This could be, for example, an MES (Manufacturing Execution System) or an ERP (Enterprise Resource Planning) system. However, individually integrated sensors can also be included. A workstation whose activities have not been recorded so far can thus be modularly equipped with a barcode scanner or RFID sensor. Due to our No-Code approach, the concrete implementation is quickly exchangeable and expandable. One would simply add existing bricks with a new address to the flow. The strong changes, which production is inevitably subject to, can therefore also be included in the flow with little change effort. The result is therefore a perfectly processed event database (so-called event log), which enables process mining to automatically generate a process model.
In addition to processing data for later analysis and finding opportunities for improvement, process mining also offers another practical benefit. Once a process model is available, it can now be checked for a newly completed job to see to what extent it conforms to the standard process or where particularly large deviations occur (so-called conformance checking).
The easy adaptability and customizability of titan can help here too. One can imagine that individual responsible persons would like to be notified if it becomes apparent that too many orders are being processed deviating from the norm. However, these alarms, notifications, and questions are also very company-specific. Depending on threshold values, parameters or actions, the bricks only have to be adapted and reconnected for further processing of the evaluation.
Finally, titan also addresses a serious problem of personal data. It is interesting to know how long which workstation has worked on which job in process analysis. However, this data can quickly be used to conclude the productivity of individual employees. In some cases, this may be desirable, e.g., to detect overloads in real-time and to be able to counteract them quickly. However, this data should not be misused for later performance evaluation. Here, titan can ensure that personal data is cut off and not forwarded and stored in the first place using individual anonymization tricks in exactly the right places. Here, too, the requirements are very individual for each company and process. Titan makes it possible to enter into dialog with the works council and data protection officers and meet their requirements even with the No-Code approach.
Adaptable data evaluation in real-time
A manufacturing operation and its associated process are subject to constant change. At the same time, it is important to know the processes and to improve them. Process mining tools can answer a wide variety of questions about processes, but they need a good database to do so.
Titan with its No-Code approach offers the possibility to collect and provide the data individually and above all customizable. The reusability of Bricks makes it possible to do this very economically and efficiently. Data composition will always change, be it new contexts to be analyzed or simply new manual workstations to be integrated. The key to success with process mining is a customizable analysis of the data in real-time.
With that in mind, I’d like to close with a quote from process mining pope Will Van der Aalst: